GAC – Tizen Client for Google Authenticator
15 Replies
You’ll need either gac-codes.txt or gac-codes.mp3 file to init accounts on your Gear device. They both have the same format, but gac-codes.mp3 makes everything easier since Samsung’s Android Gear app has capability to transfer MP3 files from a phone to your Gear device out of the box. After Android’s GAC Services app has been released, the easiest way to create the MP3 file is to use this app, since it has many features including QR Bar Code scan.
Creating gac-codes.mp3 file with the GAC Services Android app is easy:

4. Press MP3 button on the bottom or select “Legacy backup” menu from the toolbar on the top of the screen.
5. Now you can use Samsung Android Gear’s App to transfer the MP3 file from your phone to a Gear device.
After you have the MP3 file on the Gear device use “Init from file” menu to initialize all your accounts.
Get your code from a Google’s 2-step verification website. Check this link for details. Now you can create a simple file on your PC with the code (or codes). The file can contain up to 20 lines looking as follows:
Account:Code
where ‘Account’ is an arbitrary short name that will allow your to memorize where this code should be used and code is the one that your retrieved from the Google’s 2-step verification web site. Example is provided below:
Google:wr2t ghj5 xz7y a64b yu34 hjkl uiop 45df
Code is usually a 32-char long string. You can use spaces for a better readability, but they will be removed by the program anyway.
After the file is created there are three ways of importing it to your Gear device:
1. Simplest Way – Creating gac-codes.mp3 File and Using Gear App.
Create the file as described above with the name – it gac-codes.mp3. You need the mp3 extension, because Gear App on your smartphone doesn’t transfer text files, so it’s a trick, but it does work.
Transfer gac-codes.mp3 file to a Music folder on your smartphone that can be connected to your Gear device using Gear App.
Use your Gear App to transfer the file to your Gear Device:
Gear App -> Send Content to Gear -> Music -> Send Tracks to Gear
2. Using Gear’s Documents Folder
This approach will work if you can connect your Gear to a device to a Windows PC through a USB port . It works for all Gear devices except Gear S2, which doesn’t support a USB connection to a PC.
You gac-codes file should be named as gac-codes.txt in this case.
Simply connect your device to the PC and copy the file to your device’s ‘Documents’ folder.
3. Using SDB tool
If don’t mind installing Gear SDK with ‘sdb’ tool in it, you can use it to transfer you gac-codes.txt file to a device’s /tmp folder:
sdb connect
sdb push gac-codes.txt /tmp/.
After either of these steps is done you can import your codes on your Gear device from Client for Google Authentication App – just tap on “Init from File” menu item
GAC-CODES File Restrictions
The following rules are enforced when a file is imported. The lines, which are not compliant with these rules will be ignored and an error will be reported.

5. Click on “Next” with the “Android” radio button selected:

6. When you see your bar code press “Can’t scan it?” link to see the code.

7. A code that you’re looking for will be displayed on the next screen

Now, when you have the new key, you can import it to your Google Authentication (GA) client. After this is done, generate a 6-digit code on your client and complete the GA setup by verifying the generated code at the following screen:

After the code has been verified, you GA client should be in sync with Google’s authentication server.
Elliptic Curve Cryptography (ECC) looks like a good alternative and a replacement for a more common RSA dominated one, especially when it comes to devices with “weak” CPU’s, the ones that you can usually find in IoT world.
ECC used to be predominantly proprietary and patented by companies like Certicom, but now there are public standards and implementations that can be used without paying expensive license fees.
The standards have been created by organizations such as Crypto Forum Research Group (CFRG), IETF’s TLS Working Group (TLS WG) and finally by the governmental standard body – NIST, which is referred often by other compliance standards such as PCI. It means that if you want to be PCI compliant and use ECC you ought to follow NIST recommendations.
What’s the problem then? – you might ask, just go ahead and use the
standards and its implementations in popular open source tools such as
OpenSSL.
The problem is that I can’t trust to any of the standard organizations listed above. Why I can’t trust them and what can be done to make your ECC solution secure in the nearest future is described below.
The abundance of materials related to the topic and its complexity doesn’t allow making this blog short, so be patient please.
Since I’ve used the word “Drama” in the title, I should probably describe actors. Not all of them are new, e.g. you can easily find popular crypto protocol participants Alice and Bob along with eavesdropper Eve in the Bruce Schnier’s “Applied Cryptography” book published in 1996.
Many things have changed since then, Alice and Bob are not just “protocol participants” anymore, they have become dangerous cyber criminals plotting something evil, while Eve has become a heroic character trying to save the world from these dangerous criminals and their vicious plots.
Eve couldn’t do much without another heroic character Jerry whose job is to make Eve even more successful by embedding back doors to crypto protocols and standards. I think, Eve would fail more often than not without Jerry’s help if criminals Alice and Bob used the right crypto algorithms and protect their private keys well all the time.
As you probably know already, I didn’t invent Jerry and new roles myself, they’ve been created by the people whose daily job is cryptography and who publish their work in serious scientific journals that I could only partially understand. Nevertheless, I think my education in applied math and practical experience are sufficient to understand where they are going to with all that.
From my side I would also add few other actors popular nowadays:
Oddly enough, the drama would not have ever happened if one of Jerry’s notorious colleagues (we’ll call him Snow White) had not decided to disclose very interesting and intriguing details about once NIST standard and RSA Bsafe’s default called Dual_EC_DRBG. The nature of the hack is explained in simple terms here. There are two points – P1 and P2 on a curve. The first is used to calculate a random value, which is a coordinate x of the production n*P1, where n can be considered as an internal state of the algorithm. P2 is used to change an internal state of the algorithm by calculating the production n*P2 and using its x coordinate as a new state.
As it was demonstrated by Dan Shumow and Niels Ferguson in 2007 and pointed out by Bruce Schneier if there was a dependency between P1 and P2, e.g. if P2 = s*P1, then calculating internal state becomes trivial – it’s an x coordinate of s*P1*n, where both P1*n and ‘s’ are known to an attacker.
Since a method of P2 selection has never been disclosed, it created suspicions that a backdoor key (see ‘s’ above) has existed and was known to the algorithm creator since day one. The same has been confirmed by Snow White. The loop has been closed and NIST had nothing better to do as removing Dual_EC_DRBG from the standard.
The other Snow White’s revelation was that RSA got $10M from Jerry’s employer to make Dual_EC_DRBG a default in their crypto library called BSafe that was successfully licensed to many commercial companies for very expensive license fees, so RSA made money from the both compromising their library with a backdoor and telling their customer how secure their solution was. What a wonderful business model! I firmly believe now that not only RSA had the best cryptographers, but very inventive and industrious business leaders as well.
The funny thing about BSafe is that thanks to Seasoned Security Consultant Jim (see above) changing defaults in existing implementations is practically impossible, because nobody wants to spend money to protect their systems against state-sponsored attacks. Remember, “it’s impossible” according to the Jim’s assessment.
I think, it’s good time to talk about NIST P-256 now. There is a reason why this particular curve is given more attention than any other NIST curve:
Looks good, right? Wrong, if you consider the fact that the method how EC parameters have been selected is not quite clear. To be more exact, it was not clear how a seed has been chosen to generate a curve parameter.
It means that a statement about P-256 being “verifiable random” is simply not true and a D. J. Bernstein’s note in a TLS WG discussion confirms that and provides a hint about Jerry’s employer involvement in this case as well.
The common suspicion here is that Jerry has tried many of them until found a weak EC curve that can be exploited in the same way as in Dual_EC_DRBG case. Since there is an opinion that there might be a “spectral weakness” in ECC (check also this), that suspicion seems quite plausible. “Spectral weakness” means that there is a uniform (?) distribution of weak EC curves that can be eventually found through enumeration in a reasonable time interval.
Drama Perpetrators
Good Samaritan John, Seasoned Security Consultant Jim and Influential Crypto Forum Chair Lars make everything even worse by pushing everyone into the direction of not doing anything. Let me explain why their rhetoric is dangerous and doesn’t make too much sense to me.
John’s statement, “I have nothing to hide from my government”, is probably OK for personal emails and social media, but it becomes less acceptable, if at all, when John is in a position of protecting a global company’s secrets. Any international company wants to keep competitors at bay and any government tries to help its major businesses as much as possible. Conflict of interests becomes obvious here and a wise CEO would definitely try to find a replacement for John as soon as possible.
Jim just wants to simplify his own life by ignoring threats coming from a government. The problem with this approach is that if one government can break a system, other governments might find a way of doing the same, as well as well heeled and organized cyber criminals that could be connected to a government. Furthermore, either a government or cyber criminals can create tools and make them available for script kiddies at which point everyone could attack the system.
Finally, my favorite actor Lars who knows very well what’s going on in his organization, who periodically listens to the Choir’s rants, but still pretends that nothing has happened and who doesn’t want to do anything to rebuild trust to his organization even in the eyes of his own co-chairs. I won’t write too much about it, I just want to refer to Alyssa Rowan’s message to a Jerry’s colleague Kevin and Lars’ response to the rant.
I won’t make any conclusion from this story, because I could not formulate it better than co-chair David McGrew did:
“The Research Group needs to have chairs that it trusts, and who are trusted by the broader IETF and Internet communities that they work with”.
Trust is a keyword here in my view.
Drama’s La Finale
If you’ve followed my line of thought to this point, you’ve probably come to the same conclusion as I already – there is no anyone who would protect your curves from Jerry:
As you see, nobody will protect your curves, except you!
To simplify our considerations we could divide all curves in two groups – random and the ones with specially selected domain parameters, e.g. NIST P-256, D.J. Bernstein’s Curve25519 and Curve41417 are “special”, while Brainpool curves are “random”.
An important requirement of Brainpool curves is that the method of parameter’s selection is clearly defined. It includes seeds that are used for deriving the parameters. They also try avoiding the following threat coming from the “special” curves:
“The primes selected for the base fields have a very special form facilitating efficient implementation. This does not only contradict the approach of pseudo-random parameters, but also increases the risk of implementations violating one of the numerous patents for fast modular arithmetic with special primes”
This requirement creates a certain “nothing up my sleeves” assurance, which is very important considering lack of trust to manually crafted curves especially when Jerry and his colleagues are involved.
Even though optimized EC arithmetic is not available for the random curves, “nothing up my sleeves” factor seems to be more important and it very much determines my personal choice.
Since in the most cases you’re not going to build an isolated crypto-system, it’s important to integrate your crypto libraries with existing system software such as Apache, Tomcat, JBoss, RoR, HAProxy and other web and application servers that you might use.
All of them use OpenSSL to do cryptography and that’s why using Brainpool curves will require an OpenSSL version that supports them. You could find the curves implemented in the OpenSSL version 1.0.2, but it’s still a beta that you probably don’t want to use in production.
My solution was to backport Brainpool curves to a stable version 1.0.1. It was not trivial, but doable. The patch against 1.0.1j is provided in the “Appendix A”.
After the new version is created you can statically link it with a web server of your choice.
You should also keep in mind that when it comes to SSL/TLS implementation, there is a possibility to use different curves for digital signature (ECDSA) and ephemeral key exchange (ECDHE).
The type of curve used for ECDSA is the one that is used as your server’s private key, while ECDHE curve should be provided as a parameter in a server configuration file, e.g. ‘ecdhe’ parameter in ‘bind’ command of HAProxy config. Please notice that NIST P-256 is a default there, just like it is in OpenSSL. I’m just saying … 🙂
To configure Apache you can use SSLCertificateFile option that points to a certificate file containing EC parameters generated by ‘openssl ecparam’ command. If you want to use brainpoolP256r1curve, you’ll need to run:
openssl ecparam -name brainpoolP256r1 -out bp_params.pem
and then copy/paste the output to your certificate file.
To use a Brainpool curve for signatures (ECDSA) you would need to generate a private key and then either use it for creating a self-signed certificate or a CSR file if you want your certificate to be signed by a known certificate authority (CA).
The problem with the latter case is that big CA’s such as Symantec/Verisign might not support Brainpool curves (even NIST curves support is relatively new for them). I didn’t check smaller CA’s yet, so there is a room for research.
Generating a private key is simple for a curve, you just need to use the same ‘openssl ecparam’ command:
openssl ecparam -name brainpoolP256r1 -genkey -out bp_key.pem
After this is done, you can generate a self-signed certificate or a CSR file just like you did it in RSA case, e.g. to create a certificate run:
openssl req -new -x509 -key bp_key.pem -out cert.pem
I’ve noticed when was going through DJB’s SafeCurves pages that there was one problem called “Twist Security”, which didn’t look good for my choice (brainpoolP256r1):
| Curve | Cost for twist rho above 2^100? | Cost for twist rho |
|---|---|---|
| brainpoolP256t1 | 2^44.0 | 2^44.0 |
Since security of brainpoolP256r1 is equivalent to its quadratic twist brainpoolP256t1, I was concerned a bit and went through different attacks that DJB described in the “Twist Security” section. The first was small-subgroup attack, which is simply not applicable to Brainpool curves due a requirement of having cofactor equal to 1.
The other two attacks are not relevant either when it comes to OpenSSL implementation, because the latter is compliant with X9 standards, which require a point-on-curve validation.
Just to be sure that it’s true for OpenSSL, I’ve checked the code and found EC_POINT_is_on_curve (see ec_lib.c module), which is called each time when a new EC point arrives.
I’ve even had a good conversation about that with TLS community and didn’t see any objections to what I found so far.
I didn’t see any other considerations that would say that there is a serious weakness in this curve.
Initial post has been published @ blogger.com, but since Google keeps deleting comments, I moved the blog to this site. Here are screen shorts that blogger.com has deleted.

A very interesting fact disclosed by a member of cryptography research community Jerome Circonflexe is that “situation with DUAL_EC_DRBG was totally obvious to researchers at the time when it was published”. It raises even more questions. If it was known from day one (year 2007) why nobody in that community including very influential CRFG had done anything to remove the scandalous standard from NIST? Everybody was silent until Snowden came with his stunning revelations. Is it a CRFG’s conspiracy (with Jerry’s employer), intimidation, or indifference to the public interests and to all the people who rely on the standard? I think, in any case they owe explanations and an apology to all of us.
Appendix A – Brainpool Backport Patch
I’ve created a patch for back-porting Brainpool curves from 1.0.2 (beta) to 1.0.1j (stable). Since I didn’t change any algorithm, but simply added barinpoolP256r1 parameters, a probability that I broke anything is negligibly small.
I’ve tested the patched version, which I call 1.0.1z, standalone and with 1.0.2. using the latter as a server. I’ve even statically compiled it with HAProxy and was able to terminate SSL using the curve for both ECDSA and ECDHE algorithms. Everything worked, no surprises have been found so far.
After you apply the patch and build your 1.0.1z version with brainpoolp256r1 in it you can verify that everything was correct by running
$ path-to-custom-openssl version
OpenSSL 1.0.1z 15 Oct 2014
$ path-to-custom-openssl ecparam -list_curves | grep brain
brainpoolP256r1: RFC 5639 curve over a 256 bit prime field
I’ve tested NIST P-256 speed with optimized EC arithmetic (enable-ec_nistp_64_gcc_128) and compared it with that of the Brainpool curve. The optimized NIST curve was 2x times faster for ECDHE and ECDSA/signing operations, but was about the same for ECDSA/signature verification. An absolute benefit was around 0.1-0.2 millisecond per operation.
I don’t think that it’s an important denominator. I’m also suspicious about optimized EC arithmetic, because if it can be optimized by an implementer, brute forcing can be probably optimized by an attacker as well, which can decrease a cost of an attack. It’s not something that has been proven, just a “common sense” reasoning.
Finally, I think, a peace of mind and a confidence that a “first person attack” is not possible is a huge benefit compare to 0.1-0.2 millis per operation. The results are below:
$ openssl version
OpenSSL 1.0.1z 15 Oct 2014
NIST curve 2x times faster for ECDH
$ openssl speed ecdhp256 ecdhbp256
Doing 256 bit ecdh(nistp256)’s for 10s:
71830 256-bit ECDH ops in 10.00s
Doing 256 bit ecdh(brainpoolP256r1)’s for 10s: 30885 256-bit ECDH ops in 10.00s
OpenSSL 1.0.1z 15 Oct 2014
built on: Sat Nov 15 13:46:22 PST 2014
options:bn(64,64) rc4(ptr,char) des(idx,cisc,16,int) aes(partial) idea(int) blowfish(idx)
compiler: cc -DOPENSSL_THREADS -D_REENTRANT -DDSO_DLFCN -DHAVE_DLFCN_H -arch x86_64 -O3 -DL_ENDIAN -Wall -DOPENSSL_IA32_SSE2 -DOPENSSL_BN_ASM_MONT -DOPENSSL_BN_ASM_MONT5 -DOPENSSL_BN_ASM_GF2m -DSHA1_ASM -DSHA256_ASM -DSHA512_ASM -DMD5_ASM -DAES_ASM -DVPAES_ASM -DBSAES_ASM -DWHIRLPOOL_ASM -DGHASH_ASM
op op/s
256 bit ecdh (nistp256) 0.0001s 7183.0
256 bit ecdh (brainpoolP256r1) 0.0003s 3088.5
NIST curve is about the same speed for signing
NIST curve is 2x times faster for signature verification
$ openssl speed ecdsap256 ecdsabp256
Doing 256 bit sign ecdsa’s for 10s: 108757 256 bit ECDSA signs in 10.00s
Doing 256 bit verify ecdsa(nistp256)’s for 10s: 50898 256 bit ECDSA verify in 10.00s
Doing 256 bit sign ecdsa’s for 10s: 91873 256 bit ECDSA signs in 10.00s
Doing 256 bit verify ecdsa(brainpoolP256r1)’s for 10s: 25161 256 bit ECDSA verify in 10.00s
OpenSSL 1.0.1z 15 Oct 2014
built on: Sat Nov 15 13:46:22 PST 2014
options:bn(64,64) rc4(ptr,char) des(idx,cisc,16,int) aes(partial) idea(int) blowfish(idx)
compiler: cc -DOPENSSL_THREADS -D_REENTRANT -DDSO_DLFCN -DHAVE_DLFCN_H -arch x86_64 -O3 -DL_ENDIAN -Wall -DOPENSSL_IA32_SSE2 -DOPENSSL_BN_ASM_MONT -DOPENSSL_BN_ASM_MONT5 -DOPENSSL_BN_ASM_GF2m -DSHA1_ASM -DSHA256_ASM -DSHA512_ASM -DMD5_ASM -DAES_ASM -DVPAES_ASM -DBSAES_ASM -DWHIRLPOOL_ASM -DGHASH_ASM
sign verify sign/s verify/s
256 bit ecdsa (nistp256) 0.0001s 0.0002s 10875.7 5089.8
256 bit ecdsa (brainpoolP256r1) 0.0001s 0.0004s 9187.3 2516.1
There was an interesting talk at DLD and a post by Rod Beckstrom back in Jan 2014. The good thing is that there is at least one influential person in the world who could generalize and formulate recent information security and privacy issues at the right abstraction level.
Yes, Internet, IoT, social networks, new “innovative” approaches to defining privacy by big Internet companies made everything very complicated. In this regard I could not agree more with a common and wide spread opinion that privacy doesn’t exist in the era of Internet. I would not even rule out more extreme opinions stating that it was intentionally created this way to facilitate information collection by governments. The recent revelations coming from NSA/RSA/BSafe scandals or Heartbleed vulnerability exploited by NSA for years can only add more food to feed these suspicions.
I think, everyone who follows the news in this domain would not and could not argue much about all of the above. The bigger question and the problem is in the area of finding remediation solutions for these dangerous global trends.
After looking at Rod’s high level plan, I’ve realized that I simply could not agree or understand how some action items can be implemented, while others make perfect sense to me. Let us take a stab at each of them:
1. “First, we must develop global definitions, norms and standards for cybersecurity”.
Yes, but it’ll require involvement of the international community, so the task will be extremely difficult if you consider how that “international community” usually works.
2. “Second, we must build global trust”
That one is absolutely naive, unrealistic and the most problematic in my view. I think, we live in a world of crumbling trust where people, states and governments do not trust to each other more than ever in the past.
When it comes to spying and collecting information a difference between friends and foes gets blurred. I’m not sure whom NSA spies more on noways – their best friend and ally German Chancellor Merkel, worst foe Russian President Putin or their own citizens. There is a reason why Europeans (and Putin) started talking about their own “independent” and isolated Internets.
That “we do not trust them” paradigm becomes a mentality and I don’t see any willingness on any side to change it somehow. It’s definitely not an issue that can be resolved by a security community or even by a bigger “international community”. I don’t know what can be done to change this. Maybe WW3 with massive use of deadly nuclear weapons would help? (It was a black humor joke just in case if somebody didn’t understand).
Yet another confusing thing here is “we”. Who are “we”? As mentioned above NSA/RSA scandal has demonstrated, there is no such a thing as “security community” speaking with a single, strong and influential voice. Single, stand alone, dispersed voices coming from people who were trying to boycott RSA 2014 conference or few well known security professionals such as Bruce Schneier were not able to make a significant impact. It’s hardly a surprise, since the area of expertise of these few decent folks has nothing to do with politics or politicians. Will latter ever listen to professionals? I have serious doubts about that.
“International community”? No, I would not put too much trust in them either – very bureaucratic, anemic, incapable and torn apart by their internal conflicts of interests.
3. “Third, we need to use transparency and economic incentives to drive to a higher level of security”
I would strongly support any kind of incentives to achieve a better security. See my comments to #4 as well.
4. “ We must build better security into the Internet itself”
Bingo! That actually should be number one on the list and it will also address a “trust” issue in the most efficient and practical manner, in the very same manner as in the case of building a very high fence to improve your relationships with a neighbor.
So my call to everyone working in the security domain (not to abstract and amorphic “we”) at this moment would be – build the fence, the higher, the better, but don’t forget about ordinary users, usability and all other “ilities” that good software architects would normally consider.
Perfect Forward Secrecy (PFS) becomes popular and its adoption rate is growing. An importance of implementing it becomes even more obvious after recent attacks on SSL such as Heartbleed.
In Hartbleed case an impact could have been leveled down if PFS had been implemented by affected parties, since compromising private SSL key would not necessary lead to a possibility of decrypting SSL traffic.
To understand an adoption rate of PFS by different sectors of economy, the first question that we would need to answer is: “What does PFS adoption mean?” It turned out that it’s not a “Yes” or “No” question and should be formulated in terms of maturity rather than in the simple “implemented”/”not implemented” terms.
There are different options that a system engineer can consider when it comes to implementation. They are not only related to security. Usability, performance and compatibility issues must be also considered if an implementer wants to have a solution that everybody will be happy with.
There are newer (ECDHE) and older Diffie-Hellman ciphers (DHE). While the former is based on Elliptic Curves and delivers a better performance, the latter has a wider support by legacy browsers.
Another aspect is related to preferred ciphers, i.e. the ones that are selected by a server when a client provides a big variety of ciphers to chose from and the server needs to decide, which one to use.
By combining two aspects described above, we could come up with the following grades for a PFS implementation:
With this ranking system in place creating a tool that analyses a state of PFS in different industries was easy. The tool assigns a grade to each tested server and calculates a handshake time, which can be compared with that for a non-PFS cipher.
Comparing a handshake time with a non-PFS ciphers can be important, because it allows estimating a possible performance impact.
A report below generated by the tool demonstrates PFS adoption by different sectors of economy. The winning sectors are: Defense, Internet, InfoSec and Education. Big financial institutions (FI) showed poor results and it’s not a surprise – FI’s are probably good in handling privacy, compliance and fraud issues where funding and resources are abundant due regulatory requirements, but when it comes to security innovations they are definitely not a leader.
On contrary, big Internet companies that have been blamed many times for poor privacy policies are doing well in the area of security engineering. No surprises here.
Big software companies that fell to the same bucket as Finance were a surprise and a disappointment. Catching up with big Internet and Defence companies might be a good idea for them.
Finally, an important issue related to perceived “performance impact” of PFS ciphers didn’t show up in the results of this testing. I think, this is because network latency is taking over of any additional overhead added by PFS ciphers. I could see that overhead when a client and a server were running on the same subnet and a handshake time was under 10ms, but for Internet connections where a handshake time grew to over 100ms, the difference between PFS and non-PFS ciphers was negligibly small and inconsistent.
The speed of SSL handshake depends a lot on a physical client and server locations, but is usually ranging from 40 ms to 700 ms. Such a big difference and inconsistency of the handshake time decreases the importance of performance considerations as well.
No tested server made it to a category #1 or #2 and this is probably because implementers wanted to have a reliable non-PFS fall-back options for legacy browsers.
The “Perfect World” category consists of three servers built in different cloud and non-cloud environments to demonstrate that grades #1 and #2 are achievable and sane. All browsers that I had on my Desktops and Laptops could connect to the servers, but testing it with all legacy browsers was beyond the scope of this exercise.
“BL Cipher” on a diagram stands for a baseline cipher. I’ve used it to find a difference between a PFS and non-PFS cipher’s handshakes, but as I’ve mentioned above there is no any evidence for Internet connections that PFS ciphers could degrade the performance.
Two conclusions that I could make out of this are:

Existing Approaches.
While everybody seemed to agree that architecture, design review and threat modelling (TM) are very important for enforcing security in SDLC process, reaching an agreement on how all these activities should be conducted is not that simple.
There is a well documented approach based on STRIDE in the scope of Microsoft’s SDL methodology, but as I wrote before, it’s probably too theoretical, doesn’t operate in terms of the real world threats (e.g. the ones described in OWASP top 10) and might not be very efficient in cases when a quick security assessment is required. Besides, I think, that sometimes DFD-based approach is not applicable at all, e.g. in cases like protocols and API’s.
Each time when somebody is telling me that I must use DFD and STIDE for a threat model, I’m referring to an excellent TM work conducted in the scope of OAuth 2.0 IETF’s project. The best thing that I like about this approach is that it doesn’t have any pseudo-scientific terminology, it’s very straightforward, it simply describes real attack scenarios in plain English and provides actionable mitigation controls.
On the other hand, I’ve seen many TM’s created using a formal SDL approach with nice DFD diagrams, trust zones and threat classifications expressed with STRIDE terminology that didn’t make too much sense to me, mostly because describing an attack in abstract categories doesn’t really help a developer to understand the threat and how it can be exploited.
Let us try to understand why the simple approach works better than other over-formalized and wanna-be scientific methods. Here are the major factors as I see them:
TM Process.
The interesting part, which can not be deduced from the described TM, is how to come up with all those threats and make it as much comprehensive as possible. In other words, a threat modeller, especially the one that doesn’t have much experience in this area might need a certain guidance, structure and discipline around finding and documenting threats. This task might become even more complicated when a threat modeller is not really involved in designing the system under review. Here are some useful tips that can help with that:
Required Skills.
A surprising fact that I’ve discovered after years of working in TM space was that the most important skill that is required to be successful in this area is not related to security, it’s about having a strong developer’s background that would allow understanding a system and technologies used to built it well.
De-composition skill is the second important one that not all developers might have, because building systems (composition) is not exactly the same as breaking them into pieces (de-composition).
Since a threat modeller would also need to suggest remediation solution and describe a new architecture with security controls in place, I think, both composition and de-composition skills are important.
When it comes to pure security skills, it’s important for a threat modeller to be familiar with real exploits, their pervasiveness in the world and evaluate their applicability to a system under review.
Knowing the latest successful attacks against similar systems running in the same operational environment or company is very benefitial as well. In each case of successful attack, a root cause needs to be found and analyzed, repeatable security patterns should be created and used as remediation controls in all new systems where they are applicable.
Conclusion.
Just like security in general, TM is not a science, it’s all about common sense, the right skills and experience. Over-formalized TM process will not necessary help, might be inefficient, produce a low quality TM and create a false sense of security.
As mentioned in “Cloud HSM – Part 2”, to start using an HSM deployed to a cloud, you’ll need to find a way of passing credentials such as a partition level password (or PIN) and a client side certificate to all HSM’s clients.
Passing this kind of secrets using common AWS mechanisms like S3 buckets, user data or baking them to AMI‘s might not be such a good idea if you consider that common “we do not trust them” mentality described in “Cloud HSM – Part1”
Since a VM in any environment, including AWS, has a number of attributes (or metadata), some of which are unique for a VM, these attributes can be used to verify an instance that is making a claim by sending an assertion to a verifying party (VP).
In static VM environments the attributes can be used to create a VM’s fingerprint and then compare that fingerprint against a white list of all trusted fingerprints stored on a VP.
Creating “white list” for all instances running in an auto-scaling group (ASG) doesn’t seem possible though due a volatile nature of some attributes such as internal/external host names and instance ID. A way around would be to make an instance verification dynamic. Fortunately, AWS API does have all necessary functions to implement a dynamic credential-less EC2 instance validation and next section provides the details.
In this approach an EC2 client would need to collect instance parameters that are both available through a meta-data interfaces on a client, which could be considered as an asserting party (AP) and through a an AWS API on a server, which can be considered as a relying party (RP). Yet another special parameter that can be accessed on both AP and RP is an internal or external IP address, which is not exactly metadata, but can be an essential part of the instance verification process.
I’m intentionally using a SAML terminology here, since an authentication and authorization scenarios described below look very similar to those of SAML.
Here are parameters that an asserting party can fetch through a meta-data interface (e.g. through http://169.254.169.254/latest/meta-data in the ‘us-east’ region):
Their counterparts could be also retrieved through AWS API (e.g. see ec2.instance.Instance object in Python’s boto library) on RP side:
IP address can be obtained through a Socket API on AP and through API’s like getRemoteAddr in JEE API or retrieved from an HTTP header ‘x-forwarded-for’ where VP’s servers are running behind proxies or load balancers.
If your RP serves secrets for many different AP’s, you might need to consider implementing additional authorization controls that would not allow a single AP to get access to all possible secrets, e.g. you might want a database server to have an access to a database credentials only, while your web server might need an access to a private key to terminate SSL.
Using AWS Roles in these cases looks like a good solution to implement a traditional RBAC approach. You’ll basically need to assign the same role to all ASG instances using IAM console, CloudFormation or other similar tools provided by AWS. A role name would need to be submitted in an assertion created by AP and verified by RP using code like follows – basically RP would need to check if an instance that submitted a request belongs to the role provided in the assertion:
public boolean inRole (Instance ins, String role) {
boolean ret = false;
IamInstanceProfile prof = ins.getIamInstanceProfile();
if (prof == null)
return false;
String arn = prof.getArn();
ListInstanceProfilesForRoleRequest req = new ListInstanceProfilesForRoleRequest();
req.setRoleName(role);
AmazonIdentityManagementClient iam = new AmazonIdentityManagementClient(new BasicAWSCredentials(appId, appSecret));
if (iam == null)
return false;
ListInstanceProfilesForRoleResult res = iam.listInstanceProfilesForRole(req);
if (res == null)
return false;
List<InstanceProfile> ipl = res.getInstanceProfiles();
for (InstanceProfile ip : ipl ) {
if (ip.getArn().equals(arn)) {
ret = true;
break;
}
}
return ret;
}
There is always a question about how reliable and secure the suggested authentication and authorization methods are. Parameters like ‘instance-type’ and ‘reservation-id’ could be considered as semi-static and as those that don’t add much entropy to the verified parameters. IP ranges can be known in advance and it will inevitably decrease the entropy as well.
To mitigate the risks RP implementers can consider reducing a time window during which a communication between AP and RP is allowed, e.g. an RP can check an instance start time through an AWS API and deny access if an instance was running too long.
Another good mitigating control could be implementing a “one-time-use” policy, meaning that an AP can get secrets from RP only one time. This can be implemented by maintaining a list of AP parameters’ hashes and denying access to those instances whose parameters’ hashes are already in the list.
Why would you need HA
While the previous Cloud HSM article was mostly covering “Why Cloud HSM is Important” topics, this one describes technical details about how Luna HA (High Availability ) cluster can be built in a cloud and provides links to scripts that could help automating and codifying a rather complicated Luna’s setup process.
It’s obvious that when you build an HA system with subsystems that rely heavily on cryptographic services built around Luna, you need to put latter to the same HA category. That’s why a single Luna appliance is not usually sufficient and you need an array (or cluster) of HSM’s that look and behave as a single one from a client’s point of view.
The first few chapters of this document cover manual Luna and Luna array configuration topics, while “Setup Automation” section describes a command line tool that allows automating the whole process by creating a JSON configuration file and running a Python script. You do need to go through manual setup topics if you didn’t have a prior experience with configuring Luna, otherwise it could be very difficult to understand how to create the JSON file and troubleshoot possible issues.
Provisioning
Unfortunately, there is no way to deploy a Luna device to a cloud in the same automated manner (e.g. through CloudFormation) as other pieces of AWS infrastructure. There is a well documented manual process for that, which is not very difficult to follow, but it’s still manual. The process is described here.
The two important things that are worth mentioning are the facts that you’ll need a VPC to deploy a Luna appliance and that you’ll need at least two devices to create an HA array.
After the appliances are provisioned to a VPC, you’ll be given managers passwords that could be used to connect to the devices remotely and perform all necessary configuration jobs.
Configuring Luna Servers
You’ll need to login to a Luna device using SSH from a client machine to perform a configuration job. I would strongly recommend to enable key based authentication on a Luna device, because most likely you’ll need to SSH to the device many times before you’re done with configuration and verification:
scp <public-cert-file-name> manager@<luna-ip>:.
ssh manager@<luna-ip>
sysc ssh pu esysc ssh pu a -f <public-cert-file-name>
where <public-cert-file-name> is a public certificate generated by a ‘ssh-keygen’ command on a client machine.
The following high level manual steps are required to configure a Luna server:
The Luna configuration process is described in details here.
Configuring Luna Clients
This one is interesting and requires some re-thinking because of differences introduced by AWS’ auto scaling groups (ASG). In a traditional ‘static’ environment each client would require a unique client certificate and an IP (or client’s host name) to be registered on a Luna server. Since EC2 instances can randomly go up and down in ASG that approach would be difficult to implement. Fortunately, there is a way around that allows sharing a single client’s certificate for the whole ASG.
The first step in configuring clients is to download and install Luna’s client tools and libraries that are available for free:
After these two components are installed, ‘vtl’ command line tool used for a client’s setup could be found at the following location on Linux: /usr/lunasa/bin/vtl. A new client certificate and a private key can be generated by running the following command:
vtl createCert -n <cert_name>
A newly generated certificate will be stored at ‘/usr/lunasa/cert/client/<cert_name>.pem’ and will need to be transferred to a Luna server for further registration:
scp /usr/lunasa/cert/client/<cert_name>.pem manager@<luna_server>:.
A trick that allows registering the whole ASG without binding a registration to an IP is to use <cert-name> as a parameter in ‘-hostname’ option and not to use ‘-ip’ option at all. It’s not obvious, but it definitely works. A command on the server will look like this:
c reg -c <client-name> -h <cert-name>
where <client-name> is a logical name that the server will use to refer the new client and <cert-name” is the same cert that we’ve just created on the client using ‘vtl’ command.
To replicate the generated certificate and private key to other ASG members you’ll need to place the generated files to /usr/lunasa/cert/client/ and to make sure that you have two following entries in ‘LunaSA Client’ section of ‘/etc/Chrystoki.conf’ file:
ClientPrivKeyFile = /usr/lunasa/cert/client/<cert-name>Key.pem;
ClientCertFile = /usr/lunasa/cert/client/<cert-name>.pem;
You’ll also need to register a Luna server on the client to be able to connect to that server:
scp manager@<luna-server-host>:server.pem .
vtl addServer -n <luna-server-host> -c server.pem
Configuring Luna HA Cluster
You’ll need at least two Luna servers configured as described in “Configuring Luna Servers” section with the following limitations:
If the conditions above are met, registering the cluster should be easy:
vtl haAdmin -newGroup -serialNum <par-ser-nbr1> -label <group-name> -password <par-pwd>
vtl haAdmin -addMember -serialNum <par-ser-nbr2> -group <group-ser-num> -password <par-pwd>
where
<par-ser-nbr1> and <par-ser-nbr1> – serial numbers of partitions included to the cluster
<group-name> – is a logical name for the newly created cluster
<par-pwd> – is a partition password
<group-ser-num> – a serial number for the newly created group (it will be displayed after the group is created by ‘newGroup’ command.
To figure out what <par-ser-nbr1> and <par-ser-nbr1> parameters are, you can run the following command on a client:
vtl verify
The output should look as below:
The following Luna SA Slots/Partitions were found:
Slot Serial # Label
==== ======== =====
1 <par-ser-nbr1> <par name>
2 <par-ser-nbr1> <par name>
Configuring Java Client
Luna’s client includes Java classes that implement traditional JCA architecture. You’ll need to include LunaProvider.jar to a classpath and modify java.security file that can be normally found at the following location: <JRE-DIR>/lib/security/java.security. The section that needs to be updated looks as follows:
security.provider.1=sun.security.provider.Sun
security.provider.2=sun.security.rsa.SunRsaSign
security.provider.3=sun.security.ec.SunEC
security.provider.4=com.sun.net.ssl.internal.ssl.Provider
security.provider.5=com.sun.crypto.provider.SunJCE
security.provider.6=sun.security.jgss.SunProvider
security.provider.7=com.sun.security.sasl.Provider
security.provider.8=org.jcp.xml.dsig.internal.dom.XMLDSigRI
security.provider.9=sun.security.smartcardio.SunPCSC
To enable Luna Provider, add the following line to the list:
security.provider.10=com.safenetinc.luna.provider.LunaProvider
Testing HA Luna from a Java application
You can find many Java sample applications under following location: /usr/lunasa/jsp/samples/com/safenetinc/luna/sample. Connecting to an HA cluster is not different from connecting to a single Luna device – you just need to know a correct Slot number that represents the Luna array. ‘vtl haAdmin -show’ command can be used to find out what HA slot number is:
[ec2-user@ip-10-0-1-225 lunasa]$ /usr/lunasa/bin/vtl haAdmin -show
================ HA Group and Member Information ================
HA Group Label: ha_group
HA Group Number: <grp-ser-nbr>
HA Group Slot #: <grp-slot-nbr>
Synchronization: enabled
Group Members: <par-ser-nbr1>, <par-ser-nbr1>
Standby members: <none>
Slot # Member S/N Member Label Status
====== ========== ============ ======
1 <par-ser-nbr1> <par_name> alive
2 <par-ser-nbr2> <par_name> alive
The slot number that you’re looking for is <grp-slot-nbr>.
If you look at Java sample found in the KeyStoreLunaDemo.java file, you’ll find the following lines :
ByteArrayInputStream is1 = new ByteArrayInputStream((“slot:1”)
.getBytes());
This is the place where you would need to use the slot number displayed by ‘vtl haAdmin -show’ command.
Setup Automation
As you’ve probably noticed already, the Luna HA setup process is rather cumbersome and doesn’t fit well to a major cloud concept that assumes a great deal of automation. I’ve tried to address the issue by creating a Python package that would allow setting up a Luna HA cluster by running a single command:
luna_mech -a -g -r <luna-array-config-file>
or, if you want to configure a single Luna appliance, you can run:
luna_mech -l -g -r <luna-config-file>
An idea here is to put all Luna parameters to a JSON file and make the Luna Mechanizer to parse and interpret it. The next step could be to in integrate the mechanizer with a CloudFormation framework.
The code can be found in a git repo @ sf.net and can be downloaded by usual means:
git clone git clone http://git.code.sf.net/p/lunamech/code luna_mech
or
git clone git://git.code.sf.net/p/lunamech/code luna_mech
Check README file for further instructions.
Security Considerations
Since a cloud environment is not commonly considered as trusted, there is still a problem of passing secrets such as an HA partition password and client side private key to ASG members. You definitely don’t want to “bake” secrets like this to an AMI or even store them in an encrypted S3 bucket, let alone putting them to unencrypted EC2’s “user data“.
I’ll try to explore other AWS specific ways of passing secrets from an internal DC to a cloud in the next blog.
Stay tuned!
Current Mindset
There is nothing new in the fact that Amazon’s folks bake new AWS features with such a speed that nobody else in various cloud communities can catch up, but the one called “Cloud HSM” is different in my view.
The reason why it’s different is that integrating a traditional Safenet HSM, Luna, with EC2 instances can add a level of assurance that will eventually change a traditional mindset.
As of today, a traditional mindset can be shortly formulated as “we do not trust them”. We do not trust them not because we think that they can’t implement security controls at the level that we have in our internal data centers, but because we don’t really know much about their security policies, processes around those policies, access controls, about what they can potentially do with our highly sensitive data and who will be responsible if that sensitive data is leaked.
The other factor of mistrust is that no matter how good or bad our internal data center’s security controls are, we’re in charge, we know exactly how they work and we can make a change quickly if we need to, while in a cloud we do not control anything and that causes a lot of fear, uncertainty and doubts (FUD), which culminate sometimes in executive’s statements like “I don’t want to lose my job”.
Possible Mitigation
I personally would not blame anyone for the described mindset, it’s normal and it’s very common for humans to try avoiding FUD by all possible means.
On the other hand, business requires agility that cloud definitely provides, and that requirement pushes envelope toward necessity of taking a bigger risk.
The biggest question here is how to make the risk manageable and the first obvious suggestion to mitigate against “we do not trust them” paradigm is to encrypt everything in transition and at rest with cryptographic keys that are not accessible by “them”.
It’s easier to say than implement that approach though, because it’s not clear how to make the keys inaccessible by “them”. You can use in house HSM of course, but you’ll need credentials of some sort to access it from a cloud and it will require storing them somewhere in an untrusted environment.
Besides, doing encryption remotely on a network appliance hosted in your data center, might not be such a good idea considering possible performance implications.
Why Cloud HSM can be a Game Changer
The beauty of Cloud HSM is that “they” (cloud folks) don’t have access to the objects stored in the HSM partitions, you’re the only one who creates and have access to them. The only thing that cloud folks can do is to delete your partition or re-initialize the appliance in some cases (e.g. you don’t pay the fees and don’t reply to multiple warnings that have been sent to you).
That fact alone puts Cloud HSM to a category of trusted infrastructure that you can rely on to securely store cryptographic keys and certificates used by EC2 instances to encrypt/decrypt data at store and to protect it in transition.
High Availability
It’s clear that in cases when a system’s high availability is required you can’t rely on a single HSM device to support mission critical cryptography. Fortunately, Cloud HSM solution does provide a method of creating a cluster with several HSM devices that look like a single device (slot) from a client’s point of view.
Possible Usage Scenario and Architecture
It’s important to have a good security controls around network level access to a cloud HSM – you don’t want to make the device accessible to the whole world. In this regard, using AWS security groups looks like a good idea.
Another approach to achieve a better security and HSM’s availability would be to create a proxy, which will be the only compute instance (or instances) that has an access to the HSM, while all other clients would need to use the proxy to access the device.
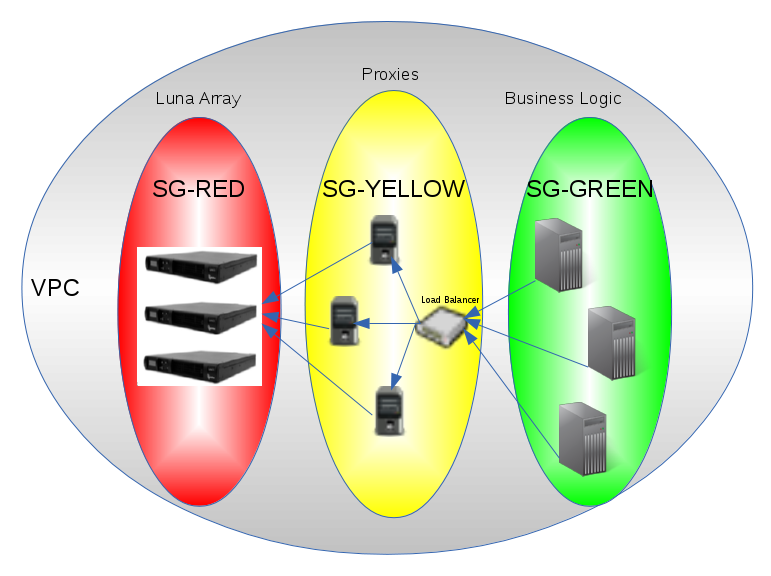
The diagram below demonstrates possible Cloud HSM architecture that solves for security and high availability of the device(s) from different AWS zones.
Security zone red (SG-RED on the diagram) will implement networking rules (ACL’s) that authorize access from the proxies only.
Security zone yellow (SG-YELLOW on the diagram) will allow connections from business layer only.
Rules defined for security zone green (SG-GREEN on the diagram) will depend on the business logic that you build.
All proxies on this diagram should be stateless and can implement additional layer of authentication for servers running in the “business logic” layer.
Limitations, Challenges
As of today, Cloud HSM is available in VPC environments only, which is a good thing from security point of view, but might not be very practical for those who want to access the device from a public cloud.
Not all AWS zones can be used to deploy Cloud HSM (I believe they are available in N. Virginia and Ireland only today).
The process of Cloud HSM provisioning is manual, so you can’t really script it by using common CloudFormation or other deployment tools.
The process of device initialization, partition creation and mutual client/server registration is rather cumbersome and includes many manual steps that in general contradict the major cloud concept that assumes automating of everything related to “infrastructure on demand” service.
All the limitations described above are resolvable though and I’ll try to describe my own experience related to that in the next “Cloud HSM How To” blog.
Stay tuned!
See also Cloud HSM – Part2